Self-Distillation Bridges Distribution Gap in Language Model Fine-Tuning
Feb 21, 2024·,,,, ,·
0 min read
,·
0 min read
Zhaorui Yang
Tianyu Pang
Haozhe Feng
Han Wang
Wei Chen
Minfeng Zhu 朱闽峰
Qian Liu
Abstract
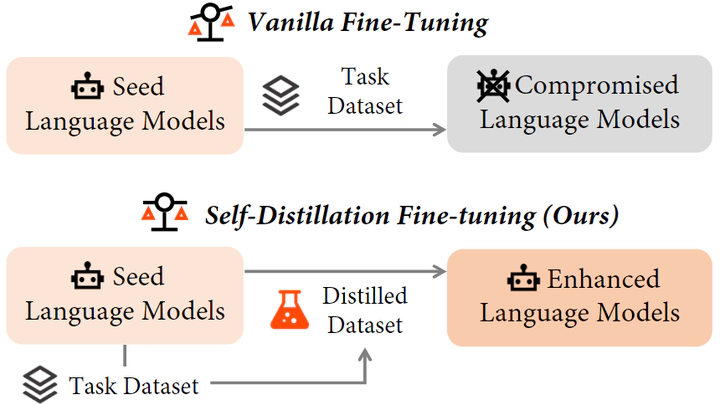
The surge in Large Language Models (LLMs) has revolutionized natural language processing, but fine-tuning them for specific tasks often encounters challenges in balancing performance and preserving general instruction-following abilities. In this paper, we posit that the distribution gap between task datasets and the LLMs serves as the primary underlying cause. To address the problem, we introduce Self-Distillation Fine-Tuning (SDFT), a novel approach that bridges the distribution gap by guiding fine-tuning with a distilled dataset generated by the model itself to match its original distribution. Experimental results on the Llama-2-chat model across various benchmarks demonstrate that SDFT effectively mitigates catastrophic forgetting while achieving comparable or superior performance on downstream tasks compared to the vanilla fine-tuning. Moreover, SDFT demonstrates the potential to maintain the helpfulness and safety alignment of LLMs. Our code is available at
.
Publication
Annual Meeting of the Association for Computational Linguistics